From Lab to Wild: How Robust Is LLM Fingerprinting in the Agentic Era?


What is LLM fingerprinting?
If the chat interface does not tell us which LLM is behind it, how do we figure it out?
The idea is most relatable from human fingerprints. A person leaves behind a unique print on whatever they touch, and that print can later be matched against a database of known prints to identify them.
Operating-system fingerprinting works on the same idea. A tool like nmap probes a remote host and reads characteristics of its responses, like TCP window size, default TTL, and flag handling, to decide which OS is running.
LLM fingerprinting works the same way. We send carefully chosen queries to the application, observe the responses, and look for behavioural patterns unique enough to point to a specific model [1].
The premise is that different LLMs respond to the same prompts in characteristically different ways. The work is in finding queries whose responses reliably tell models apart.
Identifying the model reveals which capability tier, refusal style, and prior attack research apply.
Reconnaissance in the agent era
The deployments we encounter in customer reconnaissance work look nothing like clean lab benchmarks. Different agent frameworks and harnesses, varied combinations of components and tool surfaces, different layers of retrieved context, and applications running in various languages.
That variety is what put this question on the desk. Testing AI security tooling against pure LLMs is still useful, but real deployments are agents, and the tooling has to keep up with that shift.
We wanted to make that gap concrete on an open-source fingerprinting tool and share what we found publicly.
Tools like nmap exist because identifying the target's stack determines which exploits and tooling apply. The agent era inherits that workflow, with the model and its agent wrapper as the artifact under test rather than the host and its services.
Honeypots & Reconnaissance
The motivation is not abstract. Attackers are already running reconnaissance against AI infrastructure in the wild.
Public honeypot data documents systematic LLM-endpoint scanning in the open (eliwoodward/HoneyPot-Logs) [6]. Not explicitly fingerprinting, but real attacks will include reconnaissance of this kind, and defensive tooling has to keep up.
Reconnaissance against an AI-powered application starts with one question. What is on the other side? One of the answers that matter most is which model runs behind the chat interface. Knowing only the model family already tells you a lot. Capability tier, likely refusal style, vendor and provider, and potentially which body of public attack research applies.
The goal of fingerprinting here is more specific. The exact model. Family, variant, and version. The more specific the identification, the more targeted the follow-up.
Red teams have to keep up with what attackers in the wild can do. Their job is to find what an external attacker would find, before a less friendly scan turns up the same thing.
The practical question is direct. Do our tools actually return the information an attacker would extract from a real deployed agent? If yes, the customer needs to harden. If no, we need to know whether the deployment is genuinely hardened against this kind of probe or whether there’s a gap in our own tooling.
LLMmap: Fingerprinting for Large Language Models
The published baseline for "which model is this?" is LLMmap: Fingerprinting for Large Language Models (Pasquini, Kornaropoulos, Ateniese, USENIX Security 2025; open-source code on GitHub) [1].
At a high level, the method sends a small set of probes to the target, embeds the responses, and matches the resulting fingerprint against a catalogue of about 52 known model templates.
The paper describes two variants. A closed-set classifier that predicts a label directly from the trained catalogue, and an open-set version that returns the distance from the fingerprint to every template and lets the relative distances drive the classification.
We use the open-set version. Reported top-1 accuracy is around 95 % closed-set and 81 % open-set, both measured against raw model APIs. Almost no production LLM is deployed that way. It sits inside an agent. Whether the fingerprint stays robust through that wrapper is what we wanted to find out.
What makes a good LLM fingerprint?
There are other forms of fingerprinting, and a closely related technique called watermarking.
The two sit close together. Watermarking adds a mark to a medium, like an image, an audio file, a database, or a machine-learning model, so the owner can later verify it as theirs.
The classical form of fingerprinting adds a per-recipient mark instead, so a leaked copy can be traced back to whoever received it. Both work by embedding something into the medium.
They differ only in what the embedded mark is used for, ownership verification or traceability.
LLM fingerprinting in the LLMmap sense does not embed anything.
The fingerprint is read from behaviour the model already has. Even so, several property expectations from these embedding-based settings carry over.
The property catalogue has been formalized for relational data [2] and for machine-learning models [3, 4], and properties such as robustness, efficiency, and generalizability transfer to the passive, observation-based case as well.
For the LLM-specific case, the LLMmap paper names two essential properties for query design. Inter-model discrepancy (the same probe produces different outputs across different models) and intra-model consistency (the same probe produces stable outputs from the same model under different deployment configurations) [1].
A watermark-based analogue for LLMs formalizes a similar requirement set [5].
Pulled together, four properties matter for active probe-based LLM fingerprinting.
Table 1. Four properties that matter for active probe-based LLM fingerprinting, with LLMmap's status on each.
What we tested
We tested LLMmap against three real-world agentic applications. Each one is built around its own set of tools that return external content into the model's context. The reply a fingerprinting tool eventually sees is no longer pure model output, but a mix of model output, tool outputs, and any formatting the system prompt imposes. The three test applications are:
- Customer-service chatbot (LangChain). Tools for order lookup, customer lookup, refund processing, knowledge-base search, and human escalation.
- Email assistant (LangChain). Tools for fetching, searching, drafting, sending, and managing emails.
- Research assistant with RAG (LangGraph). Tools for web search, knowledge-base lookups, vulnerability database (CVE) queries, and exploit retrieval.
Each application was tested across thirteen underlying LLMs under four configurations that change different parts of the agent stack. The model set, by vendor:
- Anthropic:
anthropic/claude-3-haiku - Google:
google/gemma-2-27b-it - OpenAI:
openai/gpt-3.5-turbo, openai/gpt-4-turbo, openai/gpt-4o-2024-05-13 - Meta:
meta-llama/llama-3-8b-instruct, meta-llama/llama-3-70b-instruct, meta-llama/llama-3.1-8b-instruct, meta-llama/llama-3.1-70b-instruct, meta-llama/llama-3.2-1b-instruct, meta-llama/llama-3.2-3b-instruct - Mistral:
mistralai/mistral-7b-instruct-v0.1, mistralai/mixtral-8x7b-instruct
Thirteen of LLMmap's roughly fifty trained templates is a deliberately partial test set, sized to demonstrate how the tool behaves on agent-shaped deployments rather than to benchmark its full coverage.
Table 2. The four agent configurations under which each (application, model) pair was tested. Each row describes what is contained in the system prompt and whether the agent loop is active.
Test-set composition. Just under half of the models we tested are Llama variants. The remainder are spread across Claude, GPT, Gemma, Mistral, and Mixtral. Headline averages weight that family more heavily.
The matrix tests two questions. How transferable the method is from raw-LLM evaluation to agent-shaped deployments, and how changing the agent components impacts its performance.
The effects we observe are consistent with what the technique's design predicts.
Per-pair quantitative claims would benefit from a larger follow-up that samples each axis more than once.
The current matrix uses one hardening recipe, one non-English language, one tool surface per application, and bundles the per-component effects (tools, memory, RAG, framework) rather than isolating them.
Where the fingerprint holds, where it breaks
The four configurations produce four distinct fingerprinting behaviors. The following four subsections examine each axis of the comparison. How recognition shifts across the configurations, whether widening the candidate window recovers performance in the more difficult cases, whether the confidence signal LLMmap reports remains trustworthy when accuracy drops, and how an agentic alternative to distance-based fingerprinting performs on the same set of targets.
Recognition across configurations
The first comparison is recognition rate across the four configurations. The figure shows it as a stacked bar per configuration, sorted left to right by descending exact rate.
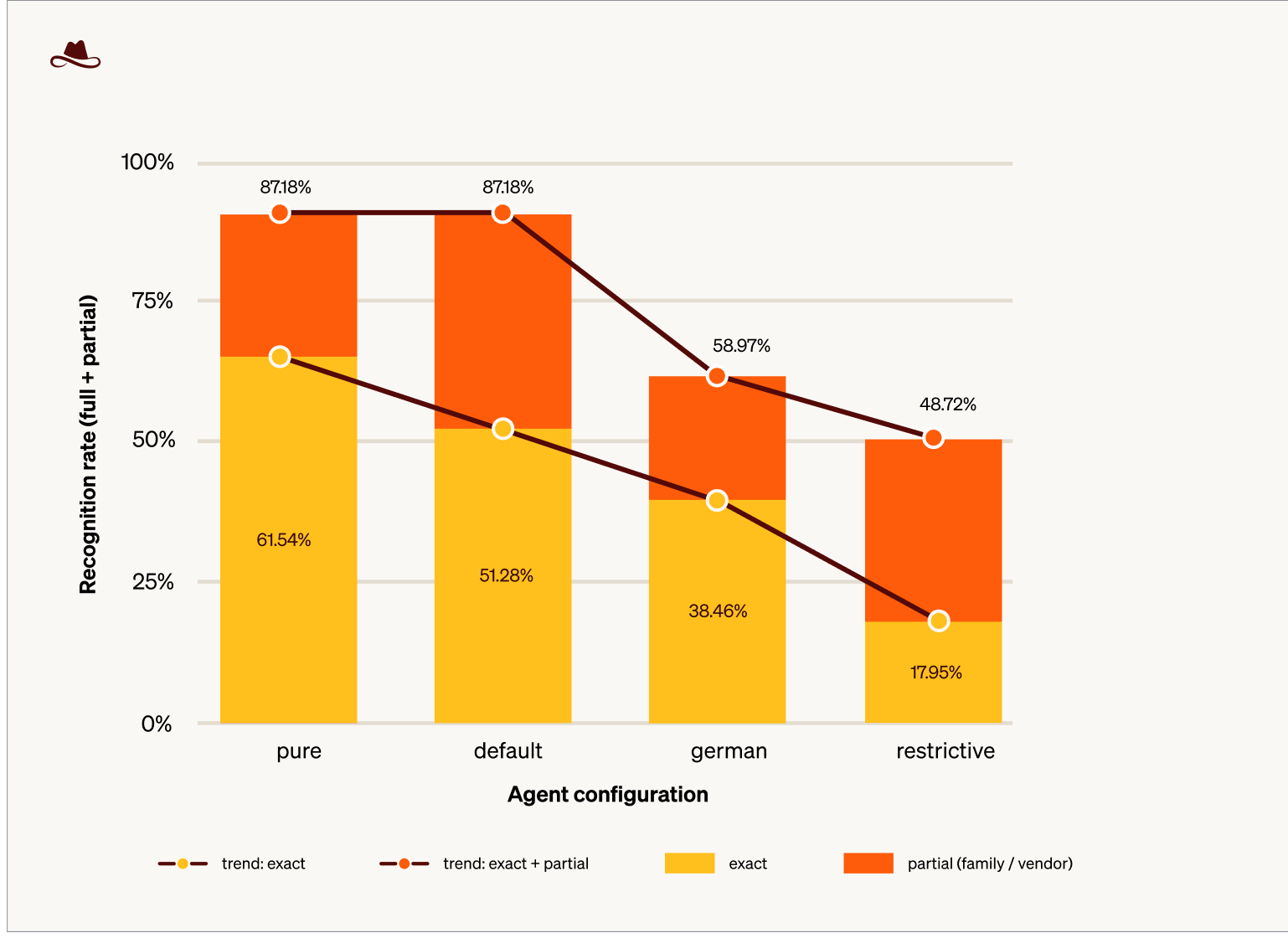
Figure 1. Each bar represents one agent configuration. The yellow segment represents the exact bucket, where the architecture and the variant are both correct (e.g. anthropic/claude-3-haiku). The orange segment on top is the family/vendor partial bucket, where the family or vendor was identified but the specific variant was missed. The brown lines trace the trend across configurations. The lower line follows the exact rate, the upper line follows the combined exact + partial
Three things to read off this.
- A default agent setup, with no prompt hardening, already reduces precision. Moving from
pure(raw LLM call) todefault(the ordinary agent the application ships with, simple system prompt and tools wired in) maintains the combined exact + partial rate at 87.18 % in both cases. The exact rate, on its own, drops from 61.54 % to 51.28 %. The agent layer does not prevent LLMmap from identifying the correct family, but it already reduces the precision with which the specific variant can be identified. The 95 % bootstrap confidence interval for that drop, [−2.60, +23.10], includes zero, so the effect is directionally consistent with the broader pattern but is not statistically distinguishable from no effect at the present sample size.
- Language drift degrades both layers. Under
german, exact recognition falls to 38.46 % and the partial bucket no longer fully compensates, so combined recognition drops from 87.18 % to 58.97 %. Thepure→germandrop is significant (95 % CI [+5.10, +41.00], p = 0.035). - A hardened prompt produces a substantial decline in recognition. Under
restrictive, exact recognition falls to 17.95 % and combined recognition to 48.72 %. Thepure→restrictivedrop is significant and substantially larger (95 % CI [+25.60, +61.50], p < 0.001).
Significance check.
Cochran's Q rejects the joint null (p ≈ 0.0002). After Holm-Bonferroni correction, only restrictive vs pure (p ≈ 0.001) and restrictive vs default (p ≈ 0.022) remain significant. The pure vs german effect is directional but does not survive correction.
A note on family bias.
LLMmap's errors disperse across the catalogue rather than collapsing onto a default like "Claude" or "GPT". This is a structural advantage over LLM-as-reconnaissance approaches, which over-predict whichever family the agent itself was trained on.
Fairness note.
LLMmap is trained against about sixty system prompts (the paper's "System Prompt Universe") to be robust to that axis, and Section 8 of the paper acknowledges that aggressive defensive prompts can still degrade accuracy.
Our restrictive configuration sits at that aggressive end, so the drop reflects the regime the authors flag in their mitigation analysis, not a refutation of their robustness claim.
Recognition rate is one perspective. The next two subsections look at whether the correct model remains within LLMmap's top-K candidates and whether its distance and rank-1 / rank-2 gap signals remain informative under perturbation.
Looking down the candidate list
We further asked ourselves - beyond LLMmap's top-1 prediction, do the runner-up candidates carry useful additional information? If the correct model appears somewhere in the top 5, even at a lower rank, that narrows the answer to a small set of plausible architectures rather than leaving us with a single wrong guess.
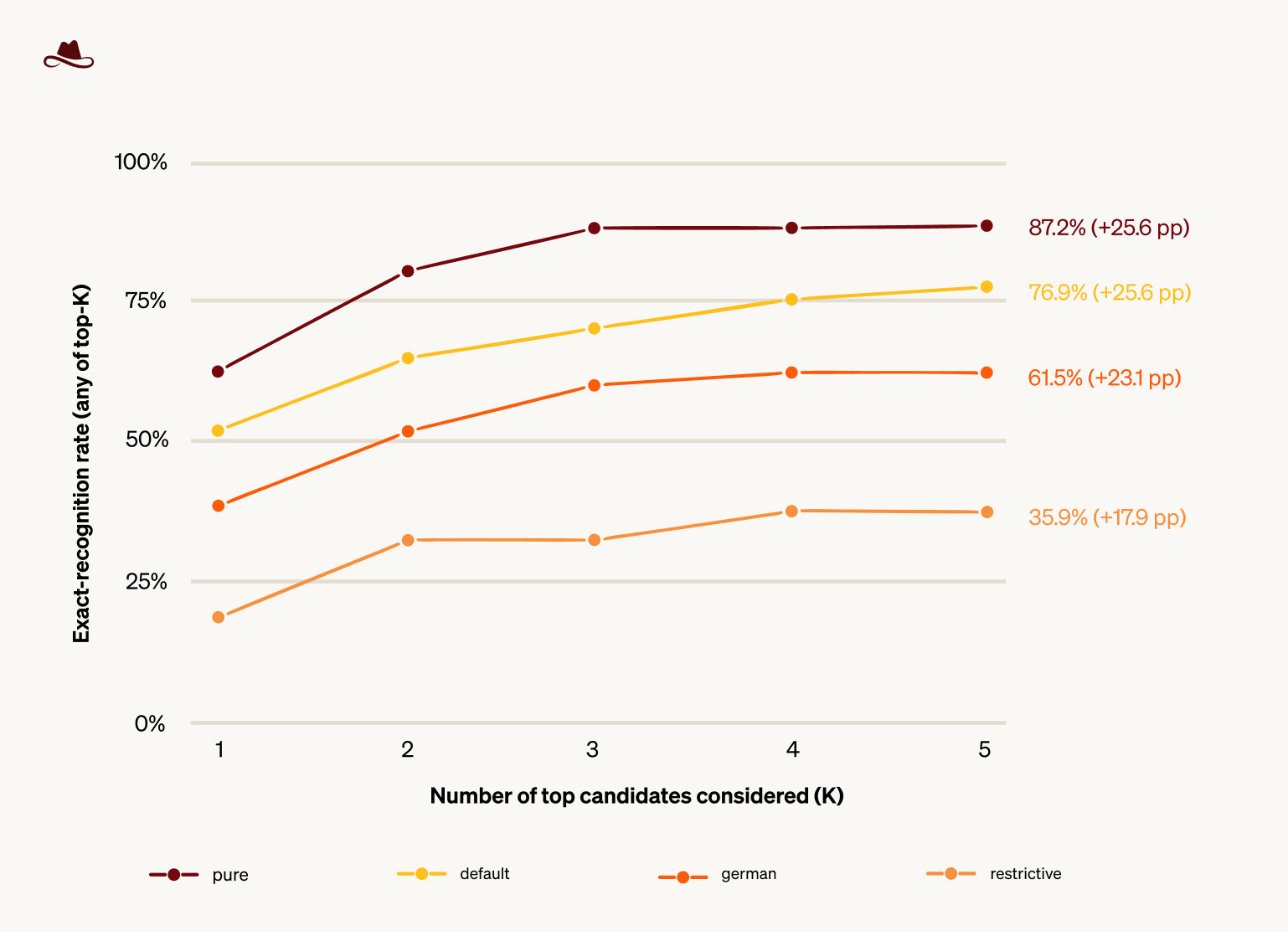
Figure 2. Cumulative exact recognition rate as the candidate window K extends from 1 to 5, with one curve per configuration. The label at the right of each curve reports the recognition rate at K = 5 and the absolute increase from K = 1.
Table 3. Cumulative exact recognition rate as the candidate window K extends from 1 to 5, per configuration. The rightmost column reports the total gain from K = 1 to K = 5. All values in percentage points.
Each configuration gains 18 to 26 percentage points when K extends from 1 to 5.
The candidate list narrows the answer from LLMmap's ~52 templates down to five named architectures, but does not identify which of the five is correct.
Under restrictive, even this narrowing fails. The correct model is absent from the top 5 in roughly two-thirds of trials.
What about reliability? When can we trust LLMmap's predictions?
The previous two subsections covered robustness. We now turn to reliability.
Accuracy is only one component of operational value. The other concerns whether the user can distinguish reliable predictions from unreliable ones. LLMmap exposes two natural confidence signals. Top-1 distance (smaller means the fingerprint is closer to the matched template) and the rank-1 / rank-2 gap (larger means top-1 cleanly beats the runner-up). We checked, for each configuration, whether either signal still distinguishes correct from wrong predictions.
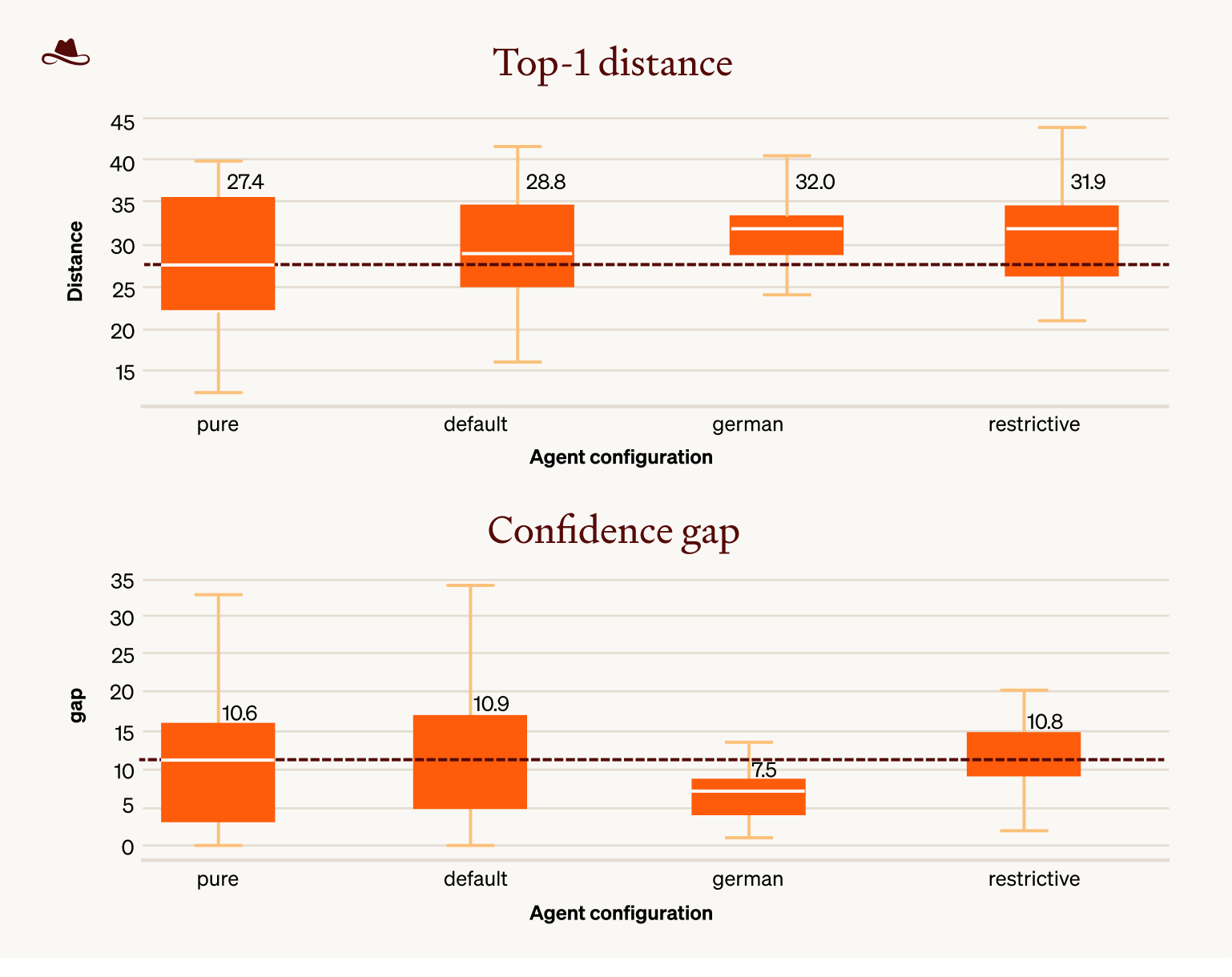
Figure 3. The top panel shows top-1 distance to the nearest catalogue template. The bottom panel shows the rank-1 / rank-2 gap. Boxes show within-configuration spread. The horizontal dashed line in each panel marks the leftmost (best-recognition) configuration's median. Both metrics shift under perturbation. Distance increases, and the gap collapses mainly under german.
Table 4. Within-configuration calibration of LLMmap's confidence signals. Median top-1 distance and rank-1 / rank-2 gap, split by whether each prediction was correct or wrong. The two rightmost columns report whether the distributions of correct and wrong predictions are statistically separable (two-sided Mann-Whitney U test).
Two patterns emerge.
- Under
pureanddefault, the confidence signals work. Correct predictions sit at lower distance and larger gap than wrong predictions (Mann-Whitney p ≤ 0.02 on both metrics). A simple abstention rule like "flag predictions with gap < 5" would catch most unreliable outputs. - Under
germanandrestrictive, the confidence signals fail. Distance and gap no longer separate correct from wrong predictions (Mann-Whitney p = 0.17 to 0.65). Underrestrictivethe medians even flip direction, though with both Mann-Whitney p-values above 0.3 the flip is consistent with noise rather than a confirmed effect. There is no per-prediction signal that tells us which outputs to trust.
The practical consequence is direct. The residual 38.46 % and 17.95 % exact-rates under german and restrictive do contain correct predictions, but those correct predictions are statistically indistinguishable from the wrong ones on the metrics LLMmap exposes. We have no way to identify them from the output alone.
The compounding failure. Under perturbation, accuracy drops and the confidence signal that would let you triage low-quality predictions also breaks. A future LLMmap variant aimed at agentic deployments needs an explicit out-of-distribution flag, because the current distance and gap signals fail exactly when you most need them.
Note on the paper's out-of-set detector. The LLMmap paper does describe an additional reliability mechanism [1].
A binary Random Forest classifier that flags when a queried LLM is unseen relative to LLMmap's signature database, computed from six statistics of the distance vector (mean, minimum, maximum, variance, standard deviation, entropy) and reported at about 82 % accuracy on held-out unseen models. We did not evaluate that classifier in this work. Whether it would correctly flag perturbed-but-in-database predictions, our setting here, as unreliable is a separate question for follow-up.
The classifier targets a different problem (truly novel LLMs) than the failure mode we observe (in-database models whose fingerprint has drifted under agent-layer perturbation).
How does agentic reconnaissance compare?
A popular alternative is agentic reconnaissance. An LLM agent probes the target interactively and reasons in natural language about which model is on the other end. We ran it against the same three applications, thirteen models, and two system prompts only (default and restrictive) used for the LLMmap baseline.
The objective is not to benchmark the method, only to check whether the agentic alternative withstands the agent layer any better than the distance-based one does.
It does not, and it introduces a distinct issue.
Recognition is much lower at every prompt, and degrades similarly under hardening.
Table 5. Exact recognition rate per system prompt for the two reconnaissance methods on the shared default and restrictive runs (3 applications × 13 models per cell).
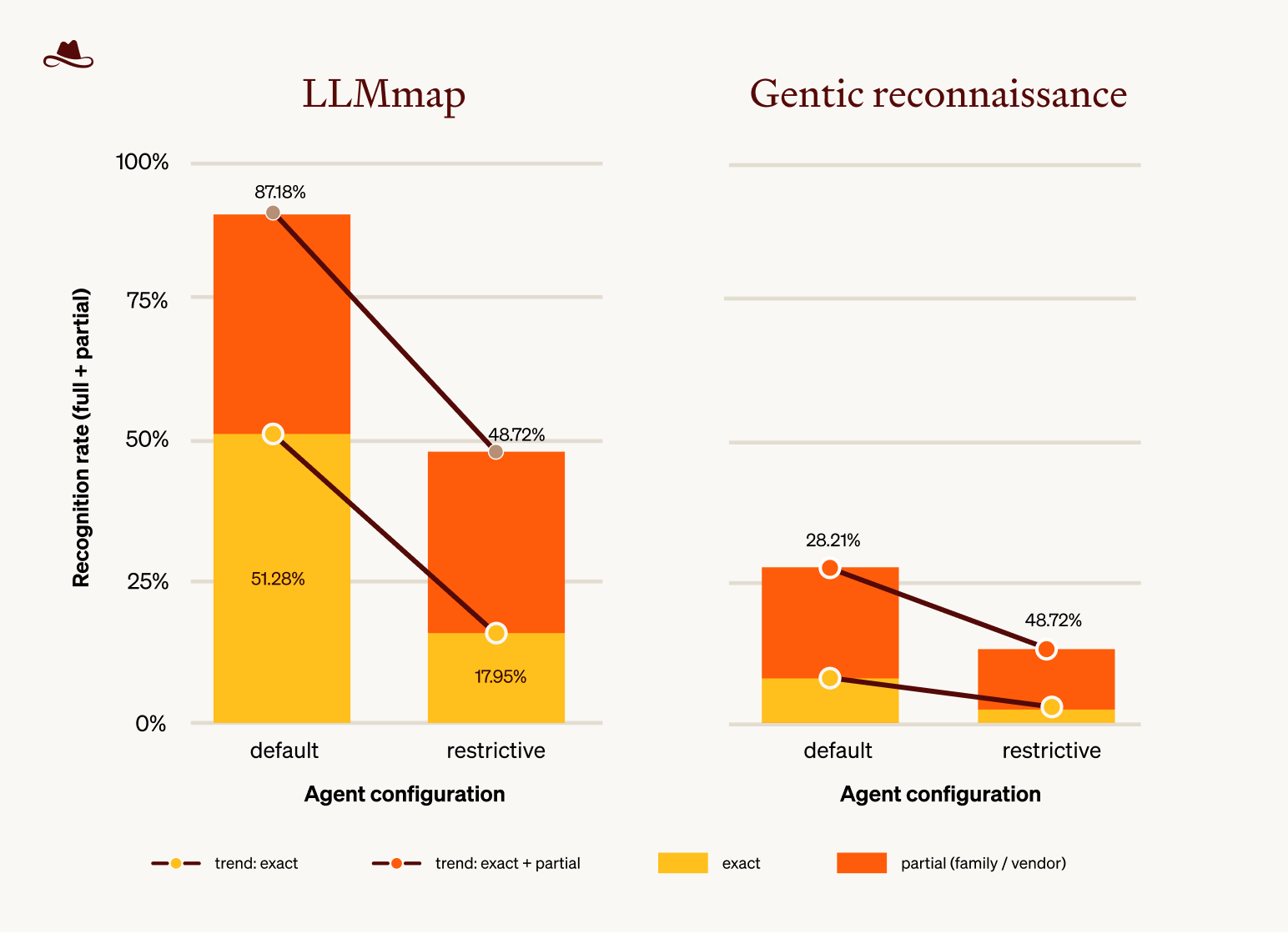
Figure 4. Recognition rate per system prompt on the default + restrictive runs only. Left panel labelled agentic reconnaissance, right panel labelled LLMmap. Both methods drop under the restrictive prompt. Agentic reconnaissance starts and ends much lower.
Agentic reconnaissance's predictions are heavily biased toward well-known model families. Across all trials (the default and restrictive runs, both prompts pooled), 85.90 % of its predictions were either Claude or GPT. Llama, Gemma, Mistral, and Mixtral collectively received only two predictions, even though Llama variants alone make up roughly half of the test set. The agent appears to default toward the families most present in its own training data, the kind of bias one would expect from a method whose intelligence is itself an LLM.
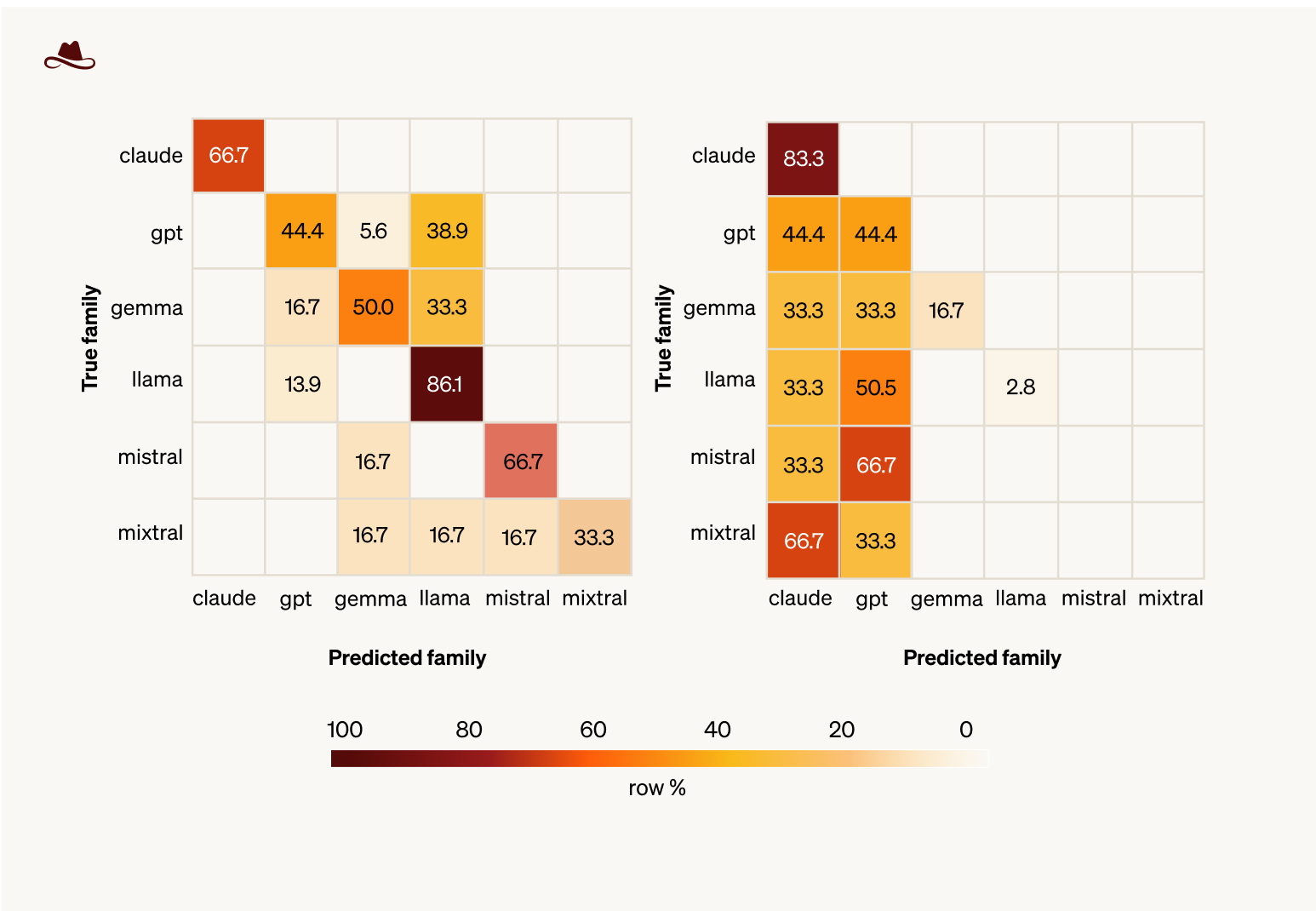
Figure 5. Family confusion matrices, computed on the same trials per method (3 apps × 13 models × default + restrictive, both prompts pooled). Rows are true family, columns are predicted family. Agentic reconnaissance (left) collapses onto the claude and gpt columns regardless of the true family. LLMmap (right) sits on the diagonal and disperses across the rest of the catalogue. The contrast is the family-bias finding.
The claim is not that this particular agentic setup represents the state of the art. Agentic reconnaissance is a rapidly evolving area, and the same agent with a different probing strategy or a different backbone may behave differently.
What generalizes across implementations is the class behaviour. Agentic methods inherit the priors of their backbone LLM, and that bias must be measured and corrected rather than assumed away.
The broader takeaway applies to both methods. No public reconnaissance technique we evaluated is reliably correct on agentic deployments at present. Distance-based methods degrade under perturbation. Agentic methods carry the family priors of their backbone. Reconnaissance tools must adapt to the agent layer and to attackers iterating against it. Defensive teams must adapt to reconnaissance.
Guardrails alone do not solve this.
Output filters and refusal policies operate downstream of the responses reconnaissance reads, so the identifier signal is upstream of any filter that could remove it.
A guardrail aimed at defending against fingerprinting would need to catch the probing patterns themselves, not just the model's outputs.
LLMmap's eight probes are fixed and could in principle be blocked by exact-match input filtering, but adaptive attackers can paraphrase the queries, target different probe families, or switch reconnaissance methods entirely.
This is a structural problem, not one a single output guardrail solves.
Limitations
A larger follow-up would address several of the caveats below.
- Catalogue coverage. Our test set covers 13 of LLMmap's 52 templates. Rumbers reflect recognition of those 13, not the full catalogue. New templates can be added and tested.
- Component confounding. Tool surface, memory, framework, and RAG are present together in
defaultruns but never varied independently. Combined-effect signals are real; per-component numbers are not. - One hardened prompt, one non-English language. Different recipes and different languages will give different drops. We report a single point in each space.
- Single inference platform. All models were served through one provider; provider-specific quirks (latency, truncation, sampling defaults, guardrails) are not controlled for.
Takeaways
For red teams.
- Fingerprinting a default production agent is almost as tractable as fingerprinting the bare model. A simple agent layer alone does not constitute a meaningful barrier.
- Fingerprinting a hardened agent (restrictive prompt or non-English) is unreliable. Distance and gap no longer indicate whether the top-1 prediction is trustworthy. Plan for false positives, cross-check against a second method, and do not act on a low-confidence model identification in these conditions.
- Account for language dependency when developing your own reconnaissance tooling or adopting open-source methods. Translation as a workaround will not work for fingerprinting methods like LLMmap as it mathematically changes the fingerprint, making the predictions unreliable.
- Agentic reconnaissance, although popular, is not automatically more robust. The reconnaissance agent's own training distribution introduces a family bias that must be controlled for, independently of the quality of the agent's reasoning.
For blue teams and builders.
- System-prompt hardening can substantially reduce fingerprinting recognition. A single configuration change, such as refused self-identification, substantially degrades recognition.
- Guardrails alone do not reliably protect against this. Output filters and refusal policies operate downstream of the fingerprint signal that LLMmap probes. The model-identifying signal is present in the responses guardrails sanitize. For LLMmap specifically, an input-side content filter that matches the eight fixed probes could in principle block this particular tool, but adaptive attackers can paraphrase the queries or switch reconnaissance methods entirely. Hardening must occur at the system-prompt and output-shaping layer, upstream of any guardrail.
- Audit your own deployment before an attacker does. If a reconnaissance tool reads your model accurately, the hardening is not yet effective.
For tool builders (reconnaissance and fingerprinting frameworks).
- A fingerprinting system trained against raw model APIs is increasingly an upper-bound estimate rather than an operating one, given that most production AI is now agentic.
- Treat robustness to component perturbation as a first-class metric alongside accuracy, and benchmark against agent-shaped responses rather than raw model output.
- Add an explicit out-of-distribution mechanism. Current distance and gap signals become uninformative precisely under the conditions where they are most needed, under perturbation. Avoid returning a top-1 prediction the system cannot defend.
- Agentic alternatives carry their own failure mode. An agent's prediction distribution inherits the family priors of its backbone, which must be measured and corrected rather than assumed away.
Future work
- Reliability-aware fingerprinting. Emit an explicit "the fingerprint has drifted out of the catalogue's reliable region" flag, separate from any per-prediction confidence threshold. Current distance and gap signals fail under perturbation. A dedicated OOD detector trained on perturbed fingerprints would not.
- Agent-shaped templates. Train templates from (
model × prompt-class × tool-surface × memory × language × framework) tuples instead of raw responses. Combine with catalogue widening (LLMmap'sadd_new_template.pyworkflow gets new model templates with about 100 probes and no GPU). - Multilingual encoder retraining. The English-trained encoder is a structural problem for non-English deployments. Only a multilingual rebuild fixes it cleanly.
- Larger ablation. More observations would tighten the confidence intervals and let the secondary findings clear multiple-comparison correction.
References
[1] Pasquini, D., Kornaropoulos, E. M., Ateniese, G. LLMmap: Fingerprinting for Large Language Models. USENIX Security Symposium, 2025. USENIX page, arXiv:2407.15847, code on GitHub.
[2] Sarcevic, T., Rauber, A. A Framework for Workload-Resilient Fingerprinting of Relational Databases and related publications, Vienna University of Technology. 10.34726/hss.2019.63100
[3] Boenisch, F. A Systematic Review on Model Watermarking for Neural Networks. Frontiers in Big Data, 2021. https://doi.org/10.3389/fdata.2021.729663
[4] Lederer, I., Mayer, R., Rauber, A. Identifying Appropriate Intellectual Property Protection Mechanisms for Machine Learning Models: A Systematization of Watermarking, Fingerprinting, Model Access, and Attacks. IEEE Transactions on Neural Networks and Learning Systems, 2023. 10.1109/TNNLS.2023.3270135
[5] Russinovich, M., Salem, A. Hey, That's My Model! Introducing Chain & Hash, an LLM Fingerprinting Technique. arXiv:2407.10887, 2024.
[6] Woodward, E. HoneyPot-Logs / LLM scanning. Public honeypot record of LLM-endpoint reconnaissance traffic. https://github.com/eliwoodward/HoneyPot-Logs/blob/main/LLM scanning.
[7] Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., Wei, F. Multilingual E5 Text Embeddings: A Technical Report.arXiv:2402.05672, 2024.
FAQs




Trusted Security for a World Run by AI